I have a question about what nodes data is downloaded from while performing initial sync.
The set up I am currently running has 4 independent nodes all running within the same VPC subnet. I have 2 stacks nodes that are fully synced which I am using as seed nodes and 1 bitcoin full node. The 4th node is a stacks node + API + postgres + explorer and the Config.toml is pointing at my own Stacks seed nodes and Bitcoin full node.
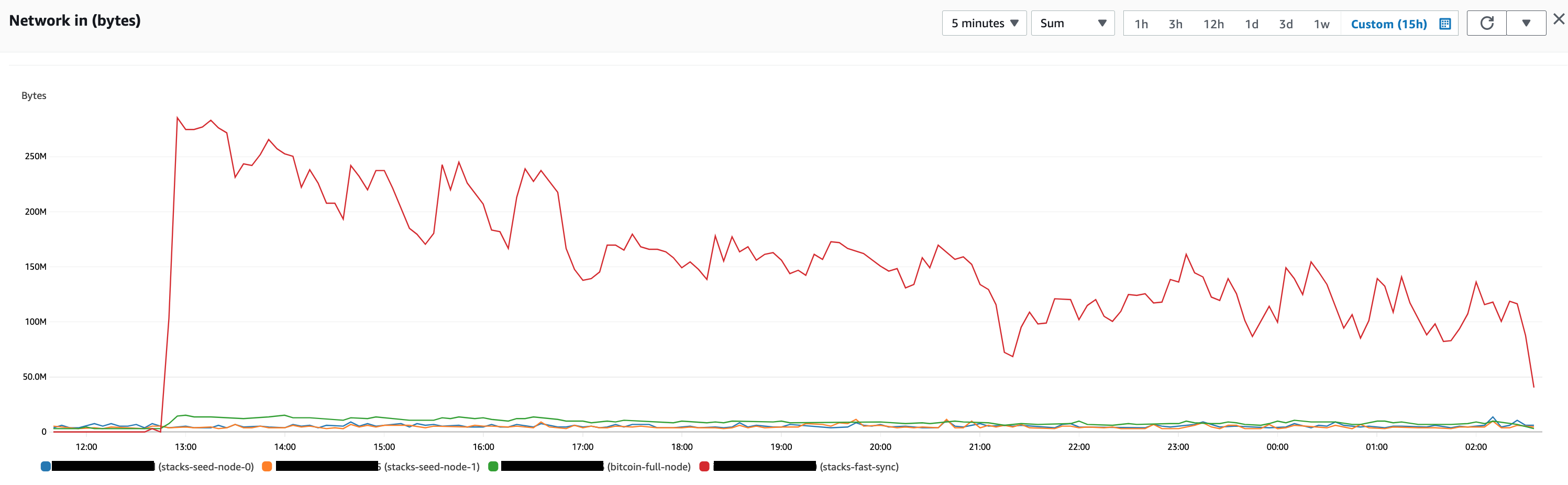
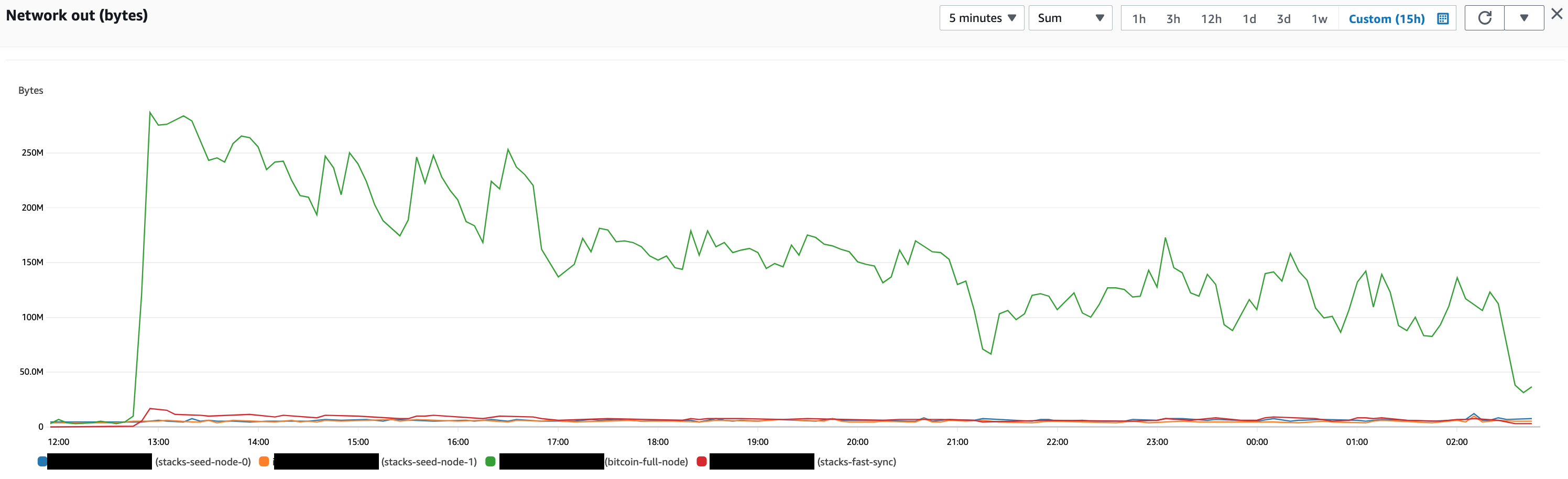
What I am observing is that almost all the data that is downloaded into the 4th Stacks node that is syncing from the beginning is really only coming from the Bitcoin full node. There is minimal data that actually is downloaded from the Stacks seed nodes.
Below charts depict this well:
My question is, are the Stacks seed nodes from Config.toml really only used to identify other peers to connect to? If so, is there a way for me to force the seed nodes to be my only peers until the full sync is complete?
Or the other possibility is what really is going on here is that there is a lot more data to download from the Bitcoin node as opposed to the Stacks nodes? If you look at the Network In data on the Stacks node it matches closely with Network Out data from the Bitcoin node. Hence thinking this could be the case.
No, and yes. The node will only do an inventory sync with the seed nodes, and thereby only learn about the availability of blocks from them. BUT, if your node is public, and other nodes do an inventory sync with your node, they may push Stacks blocks to you that you don’t yet have. But, this is a much lower-bandwidth activity than your node downloading blocks and microblocks; the latter is mainly used to help fully-sync’ed miner nodes quickly discover newly-mined blocks.
Yup, this appears to be the case. There’s only about 1 GB of raw Stacks block data total right now (730MB of blocks and 286MB of microblocks). But, it takes time to process it. Unlike Bitcoin, the size of a Stacks transaction is not related to how much CPU, RAM, and I/O it takes to process.
Also, because each PoX reward cycle’s sortitions can only be evaluated once the prior reward cycle has been processed, there block download logic is limited to downloading a reward cycle’s block data only once it has evaluated its PoX anchor block. This is because it needs the data in the PoX anchor block to determine which block-commits in the next reward cycle are even valid.
Thanks @jude for your insights and your time. I will document that sync process you laid out in Twitter and find a way to make it available for anyone looking. It seems you may have zeroed in on the issue in your twitter responses. Next step is to try switching to a provisioned IOPS setup to see if this goes any faster. Specifically the Stacks node that is syncing as well as the Bitcoin full node seems could use provisioned IOPS.
Will experiment some more and publish the results in Twitter @burnchain !!
Also per suggestion from igorsyl I have made the seed nodes I am running public and intend to make that available for others to use so the community has further options for seed nodes they can use to get bootstrapped.
One question if I may. I understand the need to download the Bitcoin blocks but why do we store the Bitcoin blocks data in the stacks node?
One might think 40 GB is not a whole lot of data in a full node but for a regular user that extra 40 GB SSD in a cloud environment costs an additional $7 or $8 per month and might make it cost prohibitive.
Not to mention this will just continue to grow as well.
It doesn’t. It only stores the (parsed) transactions that are stacks BTC operations.
The bulk of the storage space requirements comes from the indexes and metadata built over the Bitcoin and Stacks state. At the time of this writing, this is about 6 GB for the Bitcoin state, and 42 GB for the Stacks state. While there’s probably a lot of low-hanging storage space savings that could be had, it just hasn’t been a high priority yet.