Updated October 1, 2021: benchmark results were updated with new results from execution of the database operations with a simulated MARF backend.
This is a first draft proposal for more accurate runtime cost assessment in the Stacks blockchain. Runtime costs are assessed in the Stacks blockchain through a dynamic cost tracker in the Clarity VM. Updates to these costs requires either execution of a cost vote or a hard fork in the network consensus. The initial costs for the Stacks blockchain were proposed and merged with the launch of Stacks 2.0, and these costs were intentionally pessimistic— erring on the side of caution prevents Stacks nodes from falling behind the rest of the network. However, these pessimistic cost estimates unnecessarily limit the throughput of the Stacks network, when even without further optimization, Stacks nodes would be able to process more transactions in each block.
These assessed costs interact with the total block limit for the Stacks chain: each Stacks block has an upper bound on the total runtime of its transactions (as well as the total number of state reads, writes, total amount of data written, and total amount of data read). Reducing the runtime cost assessed for functions will allow those functions to be invoked more times per block, meaning that a block could fit more transactions (without otherwise changing the block limit). Initial analysis performed by Hiro suggests that 80% of transactions on mainnet are limited by their runtime costs, not by their database interactions.
For more information about how this proposal was constructed, runtime costs were measured, and to follow along or suggest changes to benchmarking, please see the clarity-benchmarking Github repository.
Determining accurate runtime costs
This proposal sets out to update the runtime cost assessed for various Clarity native functions. The other dimensions of Clarity execution costs are unchanged: the number of MARF reads, the number of MARF writes, the length of any state writes, and the length of any state reads. This is because those 4 other dimensions are measured accurately.
The goal of this proposal is to make the total real runtime of a full block less than 30 seconds. 30 seconds is a short enough period of time that prospective miners should be able to process a new block before the next Bitcoin block 95% of the time (exp( -1/20 ) ~= 95%).
To determine a new proposed cost for a Clarity function, we executed a set of benchmarks for each Clarity cost function in the clarity-benchmarking Github repository. After running these benchmarks, constant factors in the runtime functions were fitted using linear regression (given a transform). These benchmarks produced regression fitted functions for each Clarity cost function, for example:
runtime_ns(cost_secp256k1verify) = 8126809.571429
runtime_ns(cost_or) = 2064.4713444648587 * input_len + 91676.397154
The runtime block limit in the Stacks network is 5e9 (unitless), and
the goal of this proposal is that this should correspond to 30 seconds
or 3e10 nanoseconds. So, to convert the runtime_ns functions into
runtimes for the Stacks network, we have the simple conversion:
runtime_stacks = runtime_ns * 5e9 / 3e10ns
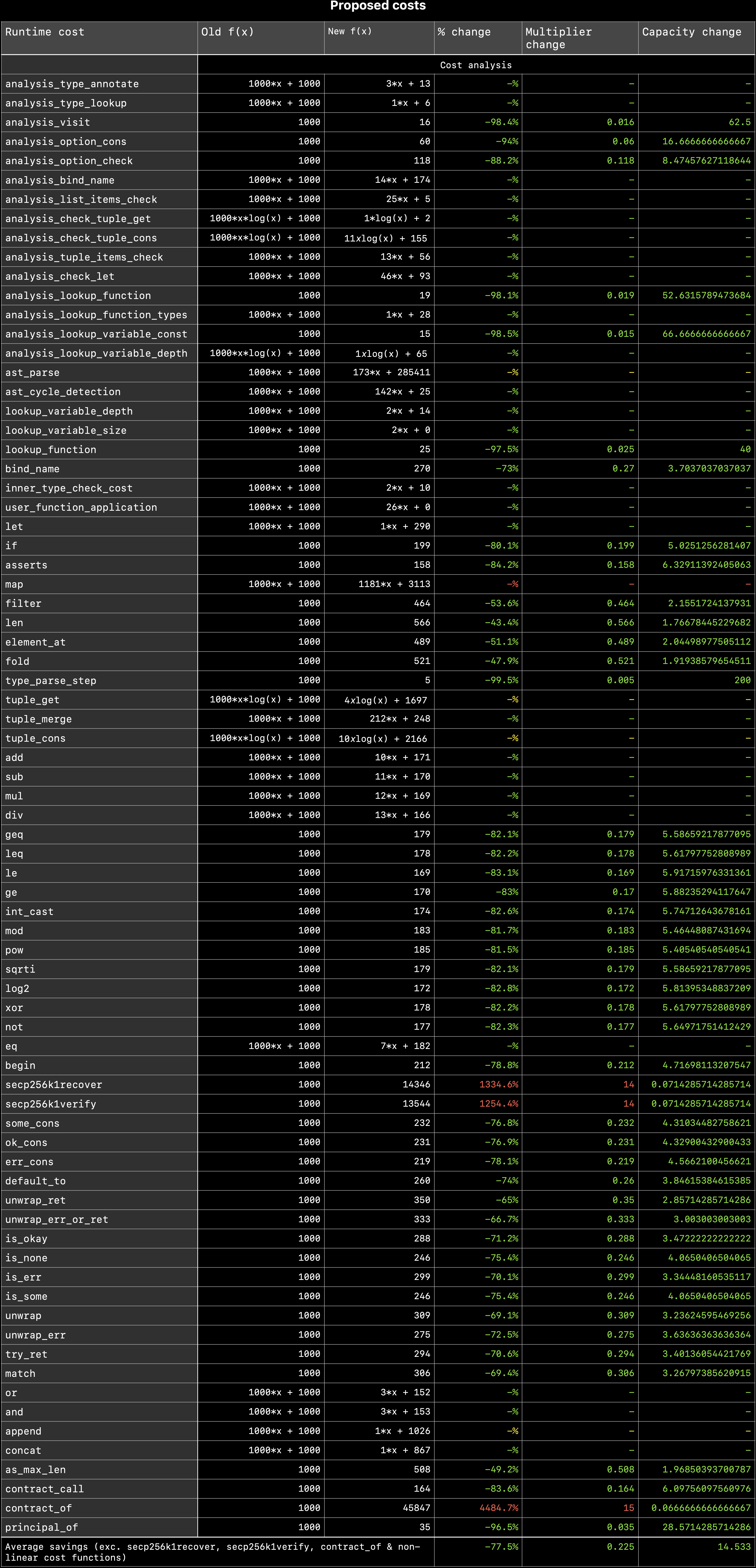
Proposed costs
| Runtime cost | New function | Old function |
|---|---|---|
| cost_analysis_type_annotate | f(x) := 3*x + 12 | f(x) := 1000*x + 1000 |
| cost_analysis_type_lookup | f(x) := 1*x + 5 | f(x) := 1000*x + 1000 |
| cost_analysis_visit | f(x) := 17 | f(x) := 1000 |
| cost_analysis_option_cons | f(x) := 51 | f(x) := 1000 |
| cost_analysis_option_check | f(x) := 131 | f(x) := 1000 |
| cost_analysis_bind_name | f(x) := 14*x + 144 | f(x) := 1000*x + 1000 |
| cost_analysis_list_items_check | f(x) := 25*x + 5 | f(x) := 1000*x + 1000 |
| cost_analysis_check_tuple_get | f(x) := 1*log(x) + 1 | f(x) := 1000*log(x) + 1000 |
| cost_analysis_check_tuple_cons | f(x) := 12xlog(x) + 64 | f(x) := 1000xlog(x) + 1000 |
| cost_analysis_tuple_items_check | f(x) := 13*x + 50 | f(x) := 1000*x + 1000 |
| cost_analysis_check_let | f(x) := 51*x + 87 | f(x) := 1000*x + 1000 |
| cost_analysis_lookup_function | f(x) := 21 | f(x) := 1000 |
| cost_analysis_lookup_function_types | f(x) := 1*x + 27 | f(x) := 1000*x + 1000 |
| cost_analysis_lookup_variable_const | f(x) := 15 | f(x) := 1000 |
| cost_analysis_lookup_variable_depth | f(x) := 1xlog(x) + 65 | f(x) := 1000xlog(x) + 1000 |
| cost_ast_parse | f(x) := 171*x + 282923 | f(x) := 1000*x + 1000 |
| cost_ast_cycle_detection | f(x) := 141*x + 26 | f(x) := 1000*x + 1000 |
| cost_analysis_storage | f(x) := 1*x + 5 | f(x) := 1000*x + 1000 |
| cost_analysis_use_trait_entry | f(x) := 9*x + 736 | f(x) := 1000*x + 1000 |
| cost_analysis_get_function_entry | f(x) := 82*x + 1345 | f(x) := 1000*x + 1000 |
| cost_lookup_variable_depth | f(x) := 2*x + 14 | f(x) := 1000*x + 1000 |
| cost_lookup_variable_size | f(x) := 2*x + 1 | f(x) := 1000*x + 1000 |
| cost_lookup_function | f(x) := 26 | f(x) := 1000 |
| cost_bind_name | f(x) := 273 | f(x) := 1000 |
| cost_inner_type_check_cost | f(x) := 2*x + 9 | f(x) := 1000*x + 1000 |
| cost_user_function_application | f(x) := 26*x + 0 | f(x) := 1000*x + 1000 |
| cost_let | f(x) := 1*x + 270 | f(x) := 1000*x + 1000 |
| cost_if | f(x) := 191 | f(x) := 1000 |
| cost_asserts | f(x) := 151 | f(x) := 1000 |
| cost_map | f(x) := 1186*x + 3325 | f(x) := 1000*x + 1000 |
| cost_filter | f(x) := 437 | f(x) := 1000 |
| cost_len | f(x) := 444 | f(x) := 1000 |
| cost_element_at | f(x) := 548 | f(x) := 1000 |
| cost_fold | f(x) := 489 | f(x) := 1000 |
| cost_type_parse_step | f(x) := 5 | f(x) := 1000 |
| cost_tuple_get | f(x) := 4xlog(x) + 1780 | f(x) := 1000xlog(x) + 1000 |
| cost_tuple_merge | f(x) := 208*x + 185 | f(x) := 1000*x + 1000 |
| cost_tuple_cons | f(x) := 11xlog(x) + 1481 | f(x) := 1000xlog(x) + 1000 |
| cost_add | f(x) := 11*x + 152 | f(x) := 1000*x + 1000 |
| cost_sub | f(x) := 11*x + 152 | f(x) := 1000*x + 1000 |
| cost_mul | f(x) := 12*x + 151 | f(x) := 1000*x + 1000 |
| cost_div | f(x) := 13*x + 151 | f(x) := 1000*x + 1000 |
| cost_geq | f(x) := 162 | f(x) := 1000 |
| cost_leq | f(x) := 164 | f(x) := 1000 |
| cost_le | f(x) := 152 | f(x) := 1000 |
| cost_ge | f(x) := 152 | f(x) := 1000 |
| cost_int_cast | f(x) := 157 | f(x) := 1000 |
| cost_mod | f(x) := 166 | f(x) := 1000 |
| cost_pow | f(x) := 166 | f(x) := 1000 |
| cost_sqrti | f(x) := 165 | f(x) := 1000 |
| cost_log2 | f(x) := 156 | f(x) := 1000 |
| cost_xor | f(x) := 163 | f(x) := 1000 |
| cost_not | f(x) := 158 | f(x) := 1000 |
| cost_eq | f(x) := 8*x + 155 | f(x) := 1000*x + 1000 |
| cost_begin | f(x) := 189 | f(x) := 1000 |
| cost_secp256k1recover | f(x) := 14312 | f(x) := 1000 |
| cost_secp256k1verify | f(x) := 13488 | f(x) := 1000 |
| cost_some_cons | f(x) := 217 | f(x) := 1000 |
| cost_ok_cons | f(x) := 209 | f(x) := 1000 |
| cost_err_cons | f(x) := 205 | f(x) := 1000 |
| cost_default_to | f(x) := 255 | f(x) := 1000 |
| cost_unwrap_ret | f(x) := 330 | f(x) := 1000 |
| cost_unwrap_err_or_ret | f(x) := 319 | f(x) := 1000 |
| cost_is_okay | f(x) := 275 | f(x) := 1000 |
| cost_is_none | f(x) := 229 | f(x) := 1000 |
| cost_is_err | f(x) := 268 | f(x) := 1000 |
| cost_is_some | f(x) := 217 | f(x) := 1000 |
| cost_unwrap | f(x) := 281 | f(x) := 1000 |
| cost_unwrap_err | f(x) := 273 | f(x) := 1000 |
| cost_try_ret | f(x) := 275 | f(x) := 1000 |
| cost_match | f(x) := 316 | f(x) := 1000 |
| cost_or | f(x) := 3*x + 147 | f(x) := 1000*x + 1000 |
| cost_and | f(x) := 3*x + 146 | f(x) := 1000*x + 1000 |
| cost_append | f(x) := 1*x + 1024 | f(x) := 1000*x + 1000 |
| cost_concat | f(x) := 1*x + 1004 | f(x) := 1000*x + 1000 |
| cost_as_max_len | f(x) := 482 | f(x) := 1000 |
| cost_contract_call | f(x) := 154 | f(x) := 1000 |
| cost_contract_of | f(x) := 13391 | f(x) := 1000 |
| cost_principal_of | f(x) := 15 | f(x) := 1000 |
| cost_at_block | f(x) := 205 | f(x) := 1000 |
| cost_load_contract | f(x) := 1*x + 10 | f(x) := 1000*x + 1000 |
| cost_create_map | f(x) := 3*x + 1650 | f(x) := 1000*x + 1000 |
| cost_create_var | f(x) := 24*x + 2170 | f(x) := 1000*x + 1000 |
| cost_create_nft | f(x) := 4*x + 1624 | f(x) := 1000*x + 1000 |
| cost_create_ft | f(x) := 2025 | f(x) := 1000 |
| cost_fetch_entry | f(x) := 1*x + 1466 | f(x) := 1000*x + 1000 |
| cost_set_entry | f(x) := 1*x + 1574 | f(x) := 1000*x + 1000 |
| cost_fetch_var | f(x) := 1*x + 679 | f(x) := 1000*x + 1000 |
| cost_set_var | f(x) := 1*x + 723 | f(x) := 1000*x + 1000 |
| cost_contract_storage | f(x) := 13*x + 8043 | f(x) := 1000*x + 1000 |
| cost_block_info | f(x) := 5886 | f(x) := 1000 |
| cost_stx_balance | f(x) := 1386 | f(x) := 1000 |
| cost_stx_transfer | f(x) := 1444 | f(x) := 1000 |
| cost_ft_mint | f(x) := 1624 | f(x) := 1000 |
| cost_ft_transfer | f(x) := 563 | f(x) := 1000 |
| cost_ft_balance | f(x) := 543 | f(x) := 1000 |
| cost_nft_mint | f(x) := 1*x + 724 | f(x) := 1000*x + 1000 |
| cost_nft_transfer | f(x) := 1*x + 787 | f(x) := 1000*x + 1000 |
| cost_nft_owner | f(x) := 1*x + 680 | f(x) := 1000*x + 1000 |
| cost_ft_get_supply | f(x) := 474 | f(x) := 1000 |
| cost_ft_burn | f(x) := 599 | f(x) := 1000 |
| cost_nft_burn | f(x) := 1*x + 644 | f(x) := 1000*x + 1000 |
| poison_microblock | f(x) := 29374 | f(x) := 1000 |
Requires more analysis
Many cost functions require more benchmarking analysis. For these methods, more analysis is needed to determine the appropriate asymptotic function and constants for capturing the runtime of the operation.
cost_list_cons
cost_index_of
cost_hash160
cost_sha256
cost_sha512
cost_sha512t256
cost_keccak256
cost_print
cost_analysis_iterable_func
cost_analysis_type_check