Yesterday was a momentous day and one for the books. 10,000 Megapont Steady Lads were up for grabs, and everyone needed one!
As I was minting a few two(and precisely 2!), an alert popped up ~6:05 PM EST about High P95 Response times. Observability for the win!
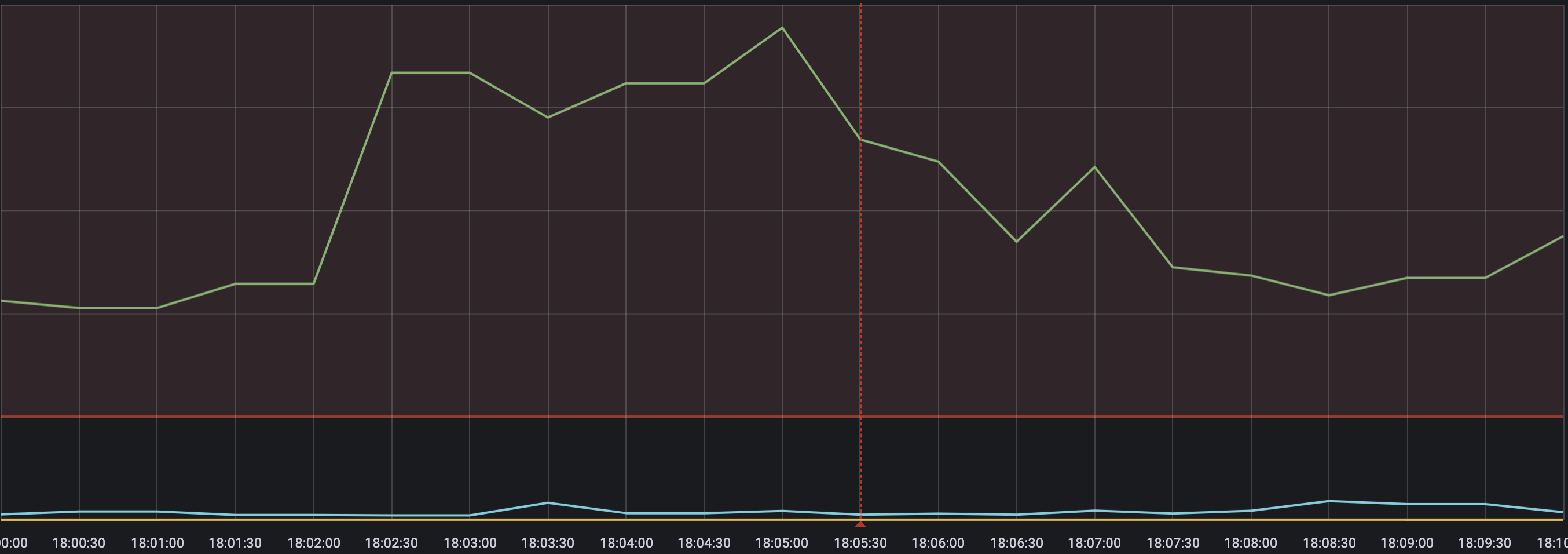
Our DevOps Team [@Charlie , @deantchi ] sprung into action to identify any bottlenecks and preemptively fix them. And we quickly identified some slow DB queries.
Note: Around this time, there were ~1000 entries in the mempool.
6:17 PM We noticed our followers were a few blocks behind the chain tip
6:51 PM We routed traffic to both our environments and noticed one environment was still 8 blocks behind whilst the other was slowly but steadily catching up
7:20 PM The environment that was struggling to catch up was also dropping peers and had 0 outbound connections
7:28 PM We routed all traffic to the environment that was just two blocks behind and started troubleshooting our other environment that was struggling to catch up
7:42 PM We identified a known issue that we also discussed in the Community Blockchain weekly and manually updated the local peer seed private key. Both the environments were back and up, caught up to the tip. We quickly saw our API back in business.
What worked?
The blocks were fuller! More deep dive on this to follow.
Our Incident response was spot on, and we could quickly identify, triage, and arrive at a fix. Our Status Page reflected the progress as we were working on the fix.
The strategy and prep work that went into scaling our API deployment paid off. We had two environments to route our traffic to and quickly routed traffic to both, taking one offline for a quick fix and then routing traffic back to both again.
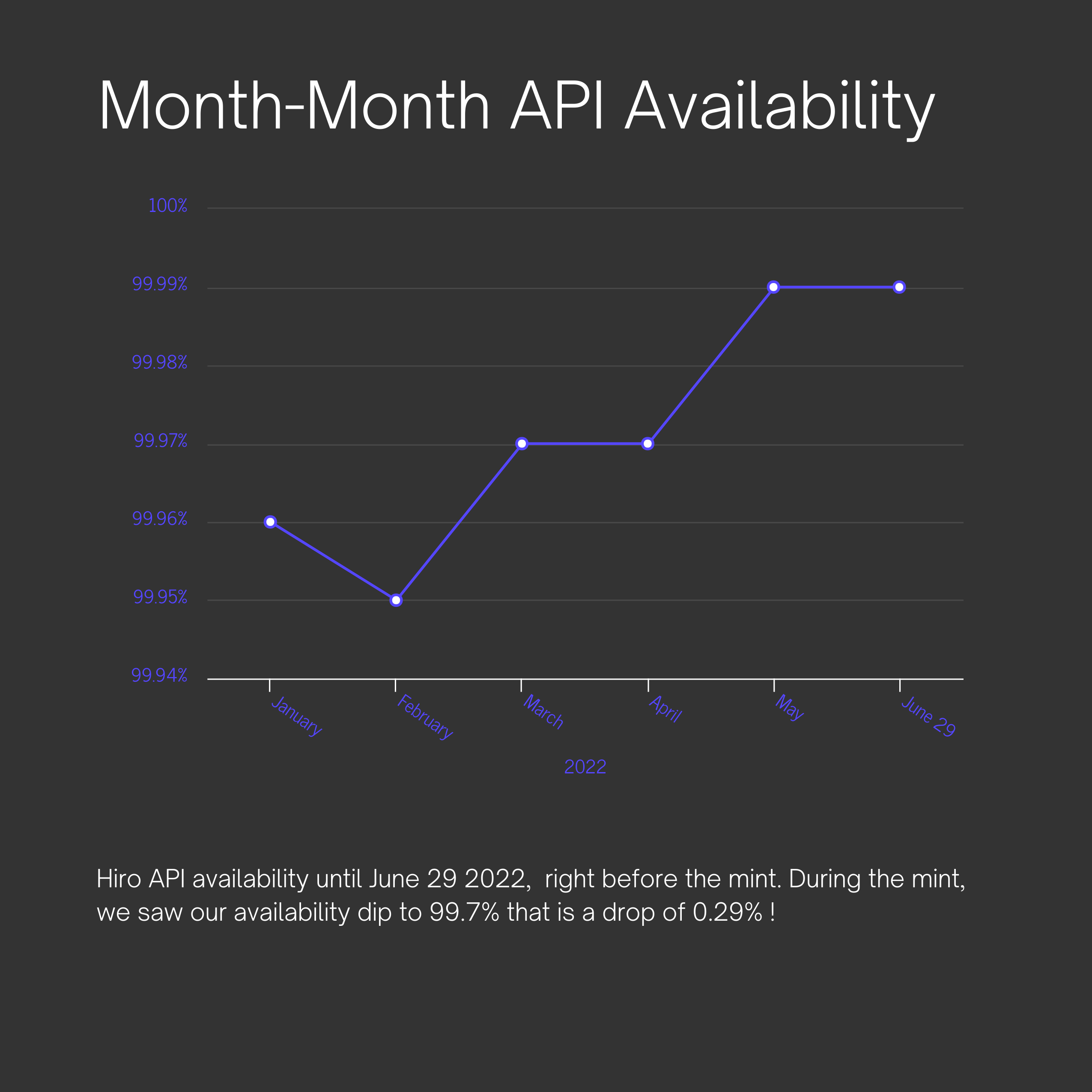
This deep dive that @Charlie shared is worth a read for more details on how we scale our API and the work that went into it. At that time of posting the Blog, our availability was 99.97% and has been 99.99% consistently over the past two months due to these improvements.
During the mint, we experienced performance degradation and served traffic with 99.7% availability.
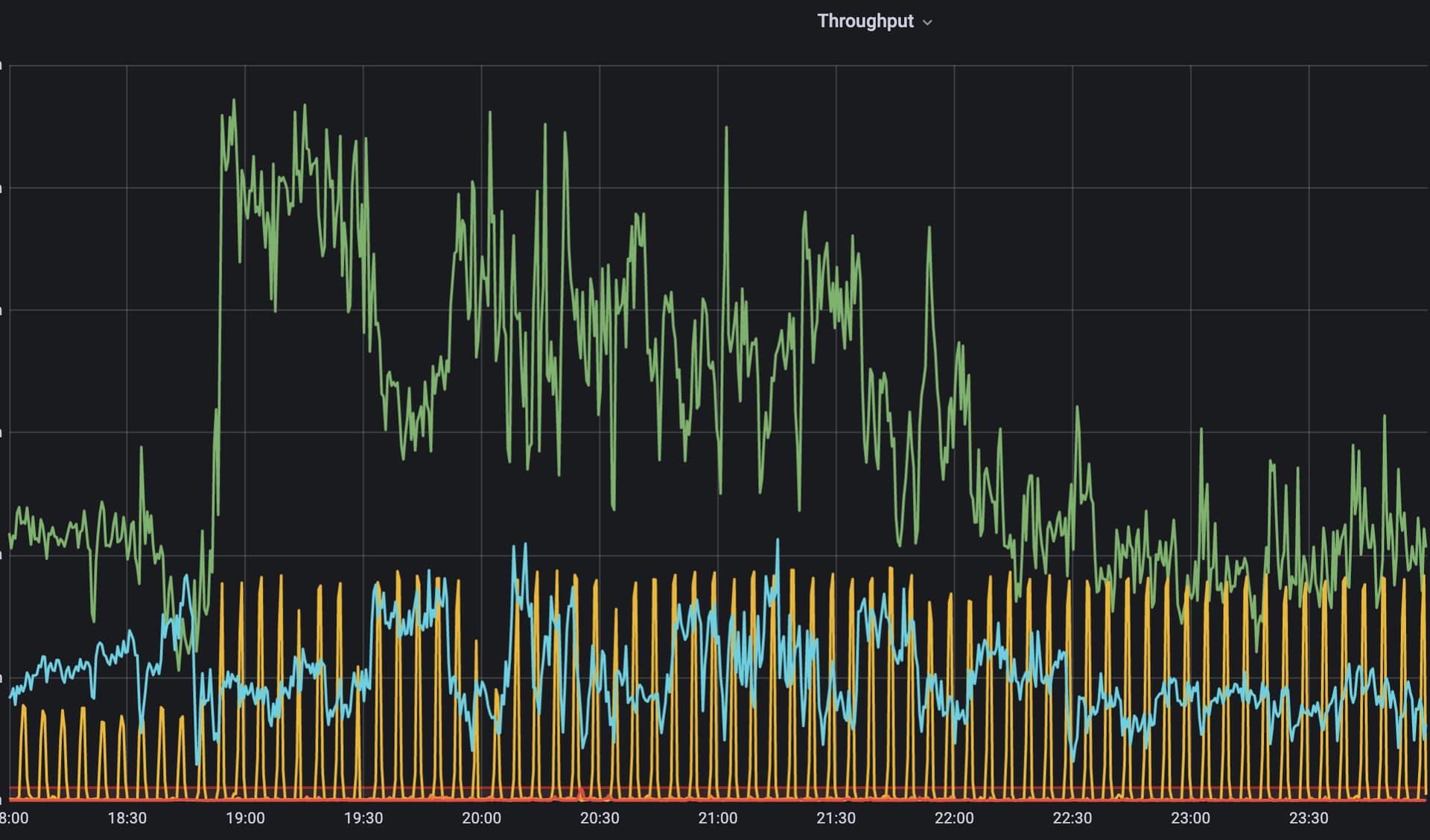
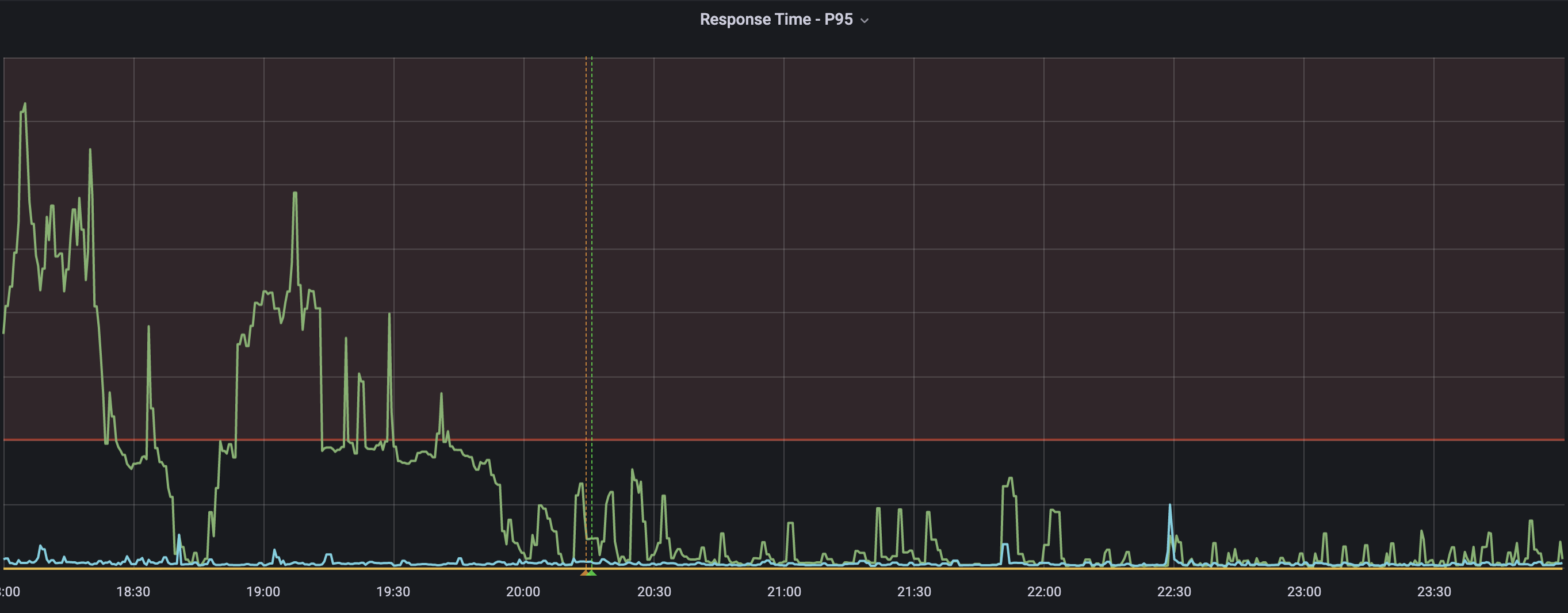
Here’s more data to paint a better picture (literally!), picture > 1000 words et al.
So far in June, our API handled 300M requests/month; >15M requests were served on June 29th.
During the mint, our API handled 28K rd/min at the peak, and between 6 PM EST - 7:40 PM EST, the API dealt with a total of 2.53M rd/m! Once the performance was stable, the API handled 32K rd/m.
History :
We started this year with ~99.6-99.7% API availability, and our API has been operating at 99.99% availability for the past 2 months.
This has resulted from continual improvements to our Architecture, Infra setup, and Observability. If past mints bear any witness, event replays and NFT endpoints were a significant bottleneck; our recovery times were a tad longer. We have since optimized our event replays [c/o @zone117x] (albeit we didn’t need one this time!), introduced new NFT endpoints [c/o @rafael ] , optimized our infrastructure[c/o @Charlie]
What’s next ?
We continue to reinforce our infrastructure and find ways to optimize the performance and observability. You can read about our continued efforts here.
If you haven’t heard, we are also working on Hyperchains [c/o @aaron] and launching an NFT Use case this month. It would be great to pressure test such a mint on a Hyperchain soon!
We love our community and your support! We are evolving and continually striving to improve our user and developer experience.
Onward and upward!